

Modern yazılım geliştirme süreçlerinde secret’ların kaynak koduna sızması, çok sık karşılaşılan ve oldukça yıkıcı bir güvenlik riskidir. CI/CD süreçleri hızlandıkça, mikroservis mimarileri yaygınlaştıkça ve geliştirici ekipleri dağıtık bir hale geldikçe bu risk oldukça artmaktadır. Bu soruna çözüm olması amacıyla açık kaynak da olmak üzere birçok araç geliştirilmiştir. Bu yazımızda açık kaynak secret scanner dünyasının yeni üyesi Hafiye’yi anlatacağım.
Benim secret scanner araçlarında gördüğüm, token gibi bir formatı olan secret’lar için başarılı oldukları ancak kullanıcının belirlediği secret’lar olan parolalar için yeterli olmadıklarıdır. Kullanıcı ya varsayılan konfigürasyonu kullanarak çok fazla secret kaçıracak, ya da konfigürasyonu genişleterek çok fazla FP ile uğraşacaktır (Birazdan bahsedeceğimiz bazı araçlarda olduğu gibi buna önlemler de alınmaya çalışılmıştır ancak kişisel tecrübem bu önlemlerin yeterli olmadığıdır). Bu sorun günümüzde LLM’ler ile çözülebilir ancak secret’lar doğası gereği gizli kalmalıdır ve bu yüzden sadece lokal LLM kullanılabilir. Ancak yalnızca bir secret scanner senaryosu için ayrı bir lokal LLM altyapısı kurmak; model barındırma, güncelleme, kaynak tüketimi ve bakım maliyetleri düşünüldüğünde çoğu kurum için rasyonel bir yatırım değildir. Böyle bir yaklaşım, ancak kapsamlı bir AppSec platformunun parçası olarak anlam kazanır. Bu sebeple standalone bir secret scanner için lokal LLM kullanımı çok iyi bir çözüm değildir. Hafiye’de bu soruna ML ile çözüm bulmaya çalıştım.
Hafiye’yi GO ile geliştirdim. GO dilini tercih etme sebebim oldukça performanslı olması ve farklı platformlar için binary oluşturmanın oldukça kolay olmasıydı. Yazılımdan siber güvenlik alanına geçmiş ve uzun zamandır kapsamlı bir proje geliştirmemiş eski bir yazılımcı olarak, vibe coding yaparken aşağıdaki gibi hissettiğimi söyleyebilirim. Yazının konusundan bağımsız, LLM’lerin geldiği noktayla temelleri ve genel konsepti bilen birisinin önünde artık bir sınır yok. Linus Torvalds’ın “Talk is cheap, show me the code” sözünün tarihe karıştığı günlere tanıklık ediyoruz.

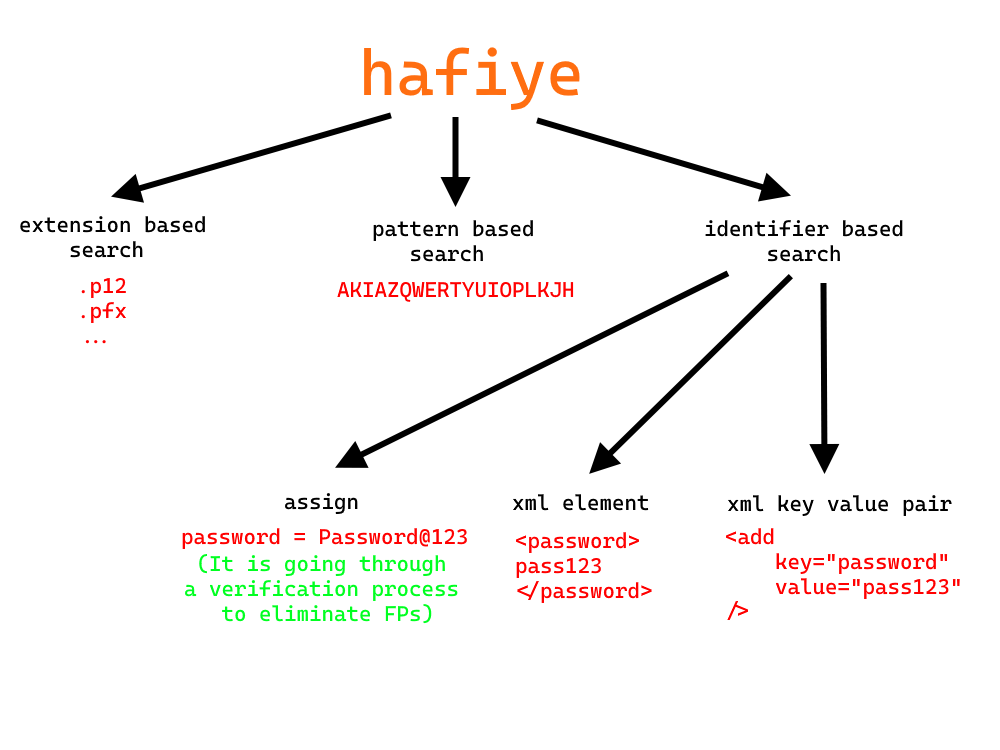
Hafiye’de aşağıda göreceğiniz üzere temelde 3 adet scanner tipi var. Birincisi, dosya uzantısına göre karar veriyor. .p12, .pfx gibi uzantıları görüp içeriğine bakmadan direkt bulgu olarak çıkartıyor. İkincisi pattern bazlı arama yapıyor yani regex’e uyan ne varsa getiriyor. Pattern bazlı arama için Gitleaks’in token regex’lerini temel aldım, FP sayısını azaltmam için bazılarını kaldırmam, modifiye etmem gerekti. Üçüncüsü olan identifier, atama tabanlı bir arama yapıyor ve deyim yerindeyse işin en ciuv ciuvlu yeri burası.
Hafiye’nin identifier tabanlı taramasına nasıl çalıştığına geçmeden önce, geliştirdiğim özellikleri neden geliştirdiğimin daha iyi anlaşılması için (pattern dışında başka birçok özelliğini de temel aldığım, diğer açık kaynak araçlara göre oldukça başarılı bulduğum) Gitleaks ile yaşadığım bir sorunu anlatmak istiyorum. Daha önceden bahsettiğim üzere bu tarz araçların varsayılan konfigürasyonları çok fazla bulgu kaçırabiliyor. Bu yüzden konfigürasyonları düzenlenebilir kılmak çok önemli, Gitleaks de bunu sağlıyor. Gitleaks’i kullanırken kullanıcıların belirlediği, herhangi bir pattern’e uymayan parolaları bulmak için regex ekledim ve Gitleaks’in sunduğu başka bir özellik olan entropy ayarıyla FP’leri azaltmaya çalıştım.
[[rules]]
id = "key-value-pair-generic-secret"
description = "Hardcoded Credentials"
regex = '''(?i)(?:\"?)(?:.*)(?:pass(wd|word|phrase)|secret|key|authorization|auth|value)(?:\"?)\s*[:=]\s*(\"[^\"]+\"|'[^']+'|[^\s]+)'''
path = '''(?i)^.*\.[^./\\]+$'''
secretGroup = 2
entropy = 3.4
tags = ["secret"]
Entropy’i çok fazla artırdığımda bulgu kaçırma oranı artıyor, düşük bıraktığımda ise FP sayısı oldukça artıyordu. Bu yüzden path ve match ignore’u ile FP’leri biraz daha azaltmaya çalıştım. İstediğim bulguları artık bulabiliyordum ancak FP sayısı yine de çok fazlaydı. Kendi secret scanner’ımı yazma kararını bu noktada verdim. Şimdi Hafiye’nin identifier bazlı tarama özelliğini konuşabiliriz.
Öncelikle identifier bazlı taramayı düzenlenebilir değil, uygulamanın içine gömülü yaptım. Bunun sebebi, konfigüre edilebilirliği sunmaya çalışırken kullanıcıyı uygulamaya özel konfigürasyonlara çok fazla boğmak istemememdi. Buna karşılık farklı türlerle karşılaştıkça alt özellikleri geliştireceğim. Mevcutta 3 alt özelliği bulunmakta: assign, xml element ve xml key value pair. Bu üç özellik de regexlere bağlı ve belli identifier’ları regex’in içine gömüyoruz. Bu identifier’lar için default değerler bulunduğu gibi identifiers parametresi (dosya, dosyadaki her satır bir identifier olacak şekilde) ile özelleştirilebiliyor. xml element yönteminde deneme identifier’ı için < deneme > my_secret < / deneme > ibaresini yakalayıp my_secret’ı secret olarak çıkartıyor. Xml key value pair’de de benzer bir durum söz konusu diyebiliriz. Bu iki alt özellikten gelen bulgular için bir FP eliminasyonu eklemedim çünkü zaten çok fazla FP üretmiyor.
assign’a gelecek olursak, password identifier’ı için password = my_secret’ı arıyor ve my_secret’ı secret olarak çıkartıyor. Ancak bu alt özellik çok fazla FP üretebiliyor. Özellikle çok fazla kod parçasını bulgu olarak getiriyor. Bu yüzden bu kategori için FP eliminasyonu ekledim. Bunun için bir makine öğrenmesi (ML) modeli kullandım. Model olarak kategorizasyonda başarılı bulduğum Random Forest’i seçtim. Uzunluk, entropy, harf oranı, sayı oranı, nokta ile bölünme sayısı gibi farklı farklı, bazılarının gerçek secret’larda fazla olacağını bazılarınınsa FP’lerde fazla olacağını tahmin ettiğim feature’lar belirledim. Eğittiğim model sayesinde edge.toString(); gibi kod parçasına benzeyen FP bulguları elemeye çalıştım (Böyle bir secret da olabilir ama bu mantıkla çok fazla FP içeren bulguyu manuel kontrol etmek gerekir. Paranoid diyebileceğimiz bu yöntemi tercih etmek isteyenler için, FP eliminasyonunu disable edilebilir yaptım. Bu halini Gitleaks’in entropy’siz versiyonu gibi düşünebilirsiniz).
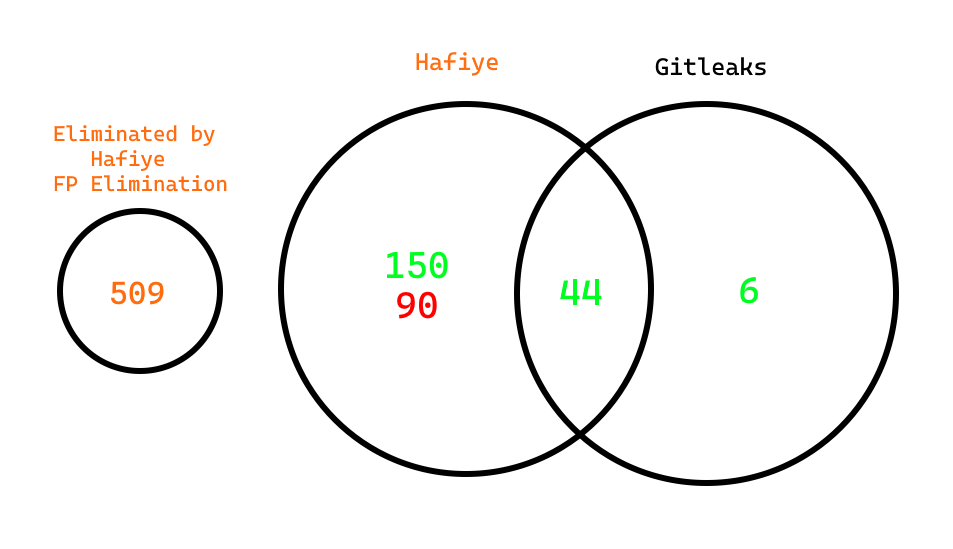
hafiye-label-train-predict adresinden ana proje için hazırlanmış mini label-train-predict projesine erişebilir, predict ile verilen secret’ın, Hafiye FP eliminasyonuna göre secret olup olmadığını kontrol edebilirsiniz. OWASP Juice Shop projesini hem Gitleaks (default config ile) hem Hafiye ile tarayıp karşılaştırdım. Hafiye 284 bulgu (90 FP, 150 Gitleaks’in bulamadığı bulgu, 44 Gitleaks’in de bulduğu bulgu) bulurken Gitleaks 50 bulgu (6 Hafiye’nin bulamadığı bulgu, 44 Hafiye’nin de bulduğu bulgu) buldu. Eğer Hafiye’nin FP eliminiasyonunu disabled’a çekseydik FP’ler ile birlikte bulgu sayısı toplamda 793 olacaktı. Bu değer, entropy bazlı eliminasyon yapan Gitleaks’te benzer konfigürasyonla yakın olacaktır. Yani başarılı bir FP eliminasyonu ile token’ların yanısıra parolaları da bulabiliyoruz demektir.
ML tabanlı çalışan FP eliminasyonum common password’leri kaçırıyorsa kaçırmasın diye eğer common-passwords (identifier gibi özelleştirilebilir) içindeyse elememesini sağladım. Bunun dışında ignore-matches, ignore-paths gibi FP eliminasyonunda kullanılabilecek diğer özellikleri ekledim.
assign identifier’ı için söyleyebileceğim son şey, kullanıcının prefixi çok fazla olabilen key gibi (aws_key, custom_key gibi) identifier’ları tekrar tekrar yazmamasını sağlamak için enable prefix özelliği ekledim. Bu enable edildiğinde regexleri dosyadaki identifierların başına herhangi bir ibare gelebilecek şekilde hazırlıyor.
Son olarak Hafiye’nin rapor formatından bahsetmek istiyorum. Fortify SSC’ye yüklenebilmesi adına SARIF çıktısı üretecek şekilde tasarladım (fortify-ssc-parser-sarif reposunu temel alarak fortify-ssc-parser-hafiye parser plugin’ini oluşturdum. Bu plugin’i Fortify SSC’ye yükleyince Hafiye çıktıları yüklenebilir hale geliyor.). Fortify SSC üzerinde özellikle hardcoded bulgularda suppresslenen (FP olarak işaretlenen) bulguların ilgili dosyada küçük bir değişiklik sebebiyle tekrar görünür hale gelmesi sorunu yaşanıyor. Bunu Hafiye özelinde çözmek için dosya ismi, eşleşen regex, secret ve rule ID kombinasyonunun hash’ini aldım ve InstanceId olarak belirledim. Temel aldığım parser plugin’inde küçük değişiklikler yaparak Fortify’da benzersiz kimliğin bu InstanceId olmasını sağladım. Bu sayede bulunduğu satırdan bağımsız bir şekilde değerlendirilmesini ve suppresslenmiş bulguların dosyadaki küçük değişiklikler sebebiyle geri gelmemesini sağladım. İki bulgu aynı InstanceId’ye sahip olamayacağı için bir dosya içinde aynı regex eşleşmesi, secret ve rule ID kombinasyonu çıkarsa bir tanesinin raporda olmasını sağladım (Bulgunun açıklama alanına birebir aynı eşleşmenin kaç defa görüldüğünü de belirttim). Bu paragraf biraz kafa karıştırıcı olabilir ancak Fortify’ın hem kendi bulguları, hem parser plugin ile gelen bulguları için bu sorunu yaşayanlar ne demek istediğimi anlayacaklardır.
Hiçbir proje için, özellikle başlangıçta mükemmel çalıştığını iddia edemeyiz. Benim de Hafiye özelinde geliştirmeyi planladığım özellikler bulunmaktadır:
- Dosya taramasının performansını artırmak istiyorum, diğer özelliklere odaklandığım için burayı çok hızlı geçtim.
- Yazıda bahsettiğim üzere identifier tabanlı taramayı eklenebilecek yeni türler keşfettikçe güncelleyeceğim.
- ML modelini geliştirmeyi, daha az bulgu kaçıracak hale getirmeyi planlıyorum.
- Bir git reposu verildiğinde, branch’leri ve tüm commit’leri tarayacak hale getirmeyi planlıyorum.
Yazımızın sonuna geldik. Buraya kadar okuduğunuz için teşekkür ederim. Hafiye’ye Hafiye adresinden erişebilirsiniz. Eğer Hafiye’yi test etme fırsatı bulursanız geri dönüşlerinizi hakany@cyberwise.com adresine iletirseniz çok memnun olurum.


{kind=link}